
| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
There is an old adage about polymorphism saying that “calls to virtual functions are slow”. However, this wisdom is conceived in the time when computers where much slower and when the difference in speed between CPU and memory was much smaller. In the meantime, many things have changed about computers. How does this wisdom hold in modern computers?
The first thing you need to understand about modern processors is that they are “data-hungry”. Modern processors are super fast, they can execute several instructions in parallel, execute instructions out-of-order for faster speed etc. But, far too often it happens that the data instructions need is not available and the processors must wait for it. Have in mind that most instructions take one cycle to execute, but in case of a data cache miss, the instruction will take two hundred cycles to execute. That’s a huge slowdown!
When it comes to polymorphism, the address of a non-virtual function is known at compile-time and the compiler can emit the call directly. The address of a virtual function is not known at compile-time and the compiler needs to figure it out during runtime. Of course it is more work to call a virtual function than a non-virtual function, but in the presence of cache misses, this difference can be negligible or can be huge.
How does a call to a virtual function typically resolve? For each class that has virtual functions, there is a virtual table (vtable) that contains the address of each of its virtual functions. Additionally, each instance of the type contains a pointer to this list (vtable*).
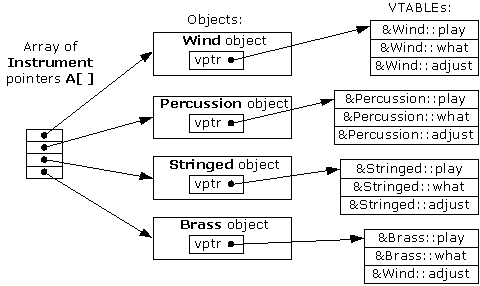
In the terms of cache behavior, we need to access both the pointer to the virtual table (which is a hidden instance member) and the entry in the virtual table. How does that relate to the cache memory?
Let’s assume that the instance data is not in the cache. Access to vtable pointer will result in a cache miss, so there will be a large delay before the function is even called. If this was a call to a virtual function done over a container of objects, and all the previous objects were of the same type, the processor could successfully speculate and start executing virtual function before the vtable pointer is even loaded. This would mask the cost of a cache miss.
Inside the virtual function, we can reasonably expect that the function accesses some instance data. Since we had a cache miss in accessing the vtable pointer, the virtual function shouldn’t have a huge cache miss since it also loaded some of the instance data together with the vtable pointer. The non-virtual function accessing instance member will need to wait for the data from the cache since there was no previous access to instance data.
Class’ vtable will probably be in the data cache most of the time since it is shared among many instances of the same class. One would need to imagine a huge hierarchy of classes that would make evicting of vtable from the cache likely when iterating over a collection of classes of different types.
Note however that this is not the end of the story. Non-virtual methods can be inlined, whereas virtual cannot. Small non-virtual methods can be easily inlined and the performance difference can be huge for small functions. Whether this will happen depends on the compiler. You can read more about inlining in the post on avoiding function calls.
So to summarize, we can expect a small difference between regular calls and calls to virtual functions when it comes to speed. But if inlining happens, the difference can be bigger. We will measure the difference later on.
Containers for polymorphic objects
A common pattern in C++ is to define a base class with a few virtual methods and several derived classed that implement the specific behavior for the methods. Next, the developer creates instances of the derived classes using new and stores them in a container as pointers to the base class. This allows the virtual method mechanism to get activated when iterating through the container. This is what we mean under container for polymorphic objects.
In the article about memory access penalties, I already explained how the data layout of your data structure influences the performance when it comes to cache hit rate. It is common knowledge that vectors or arrays are the best containers to store data for optimal cache use. In that case, the HW prefetcher figures out that we are accessing data one by one and prefetches the data before we even need it. This is a huge boost to your program’s performance.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Array of pointers to objects
When it comes to arrays of polymorphic objects, however, there is a problem in C++. Natural way to store polymorphic objects is to store it as an array of pointers to the base class. Or in C++ words: std::vector<base_class*>. In that when you iterate through the array and calling a virtual method, it will be dispatched properly.

However, this approach is not always data-cache friendly. Neighboring pointers don’t necessarily point to the neighboring memory chunks. If they do, the speed is comparable to value arrays. If not, slowdowns can be drastic.
We did some measurements to verify this. We created an array of 20M objects. They were four kinds of objects: rectangle, line, circle and monster, all four deriving from the class object. We measured the time needed to finish 20M calls to three methods: draw (virtual, long), get_id (virtual, short) and get_id2 (non-virtual, short). Here are the numbers:
| Pointers in array point to neighboring chunks | Pointers to array point to non-neighboring chunks | |
| draw runtime (virtual, long) | 2660 ms | 16905 ms |
| get_id runtime (virtual, short) | 384 ms | 5067 ms |
| get_id2 runtime (non-virtual, short) | 369 ms | 6045 ms |
As you can see, on my iCore i5-10210U processor, the difference in speed is huge. In your particular case, the speed will be somewhere in between these two extreme values.
So if you want speed, you need to pay attention to the memory layout. Custom allocator for your data structure would prove indispensable to guarantee the performance.
Array of values: std::variant
Even though the array of pointers is the most natural way to keep an array of polymorphic objects, in terms of speed it can be quite bad. The next thing that comes to mind is keeping the values instead of pointers. Unfortunately, things get complicated from that point on. There is no simple built-in way in C++ to do this.
C++17 introduced a new type called std::variant which is a fancy C style union. For example, std::variant<parent_class, child_class1, child_class2> will store either an instance of parent_class or an instance of child_class11 or an instance of child_class2. But you will need to write a conversion to parent_class* manually in order to call though virtual functions mechanism. Here is an example from our code (object is parent class, others derive from it):
std:.vector<std::variant<circle, line, rectangle>> v;
v.push_back(circle(point(20, 20), 10));
v.push_back(line(point(0, 0), point(10, 10)));
v.push_back(rectangle(point(0, 0), point(10, 10)));
for (int i = 0; i < v.size(); i++) {
to_base(v[i])->draw(b);
}
object* to_base(std::variant<object, line, circle, rectangle, monster>& v) {
if (std::holds_alternative<line>(v)) {
return &std::get<line>(v);
} else if (std::holds_alternative<circle>(v)) {
return &std::get<circle>(v);
} else if (std::holds_alternative<rectangle>(v)) {
return &std::get<rectangle>(v);
} else {
return nullptr;
}
}Function to_base does the conversion, but as you can see, it is just a huge if that deals with each individual type. Not very elegant.
Array of values: std::variant with std::visit
Following a comment made by a reader, dispatching of methods for std::visitor is meant to be done by std::visit. The implementation from the previous section is naive, because it actually dispatches a method two times: once when we use std::holds_alternative to figure out the underlying type, second time when we call the method through object base class.
Here is the implementation that uses std::visit:
std:.vector<std::variant<circle, line, rectangle>> v;
v.push_back(circle(point(20, 20), 10));
v.push_back(line(point(0, 0), point(10, 10)));
v.push_back(rectangle(point(0, 0), point(10, 10)));
for (int i = 0; i < v.size(); i++) {
std::visit([&](auto& s) { s.draw(b); }, v[i]);
}The syntax is very elegant.
Array of values: our implementation
So we’ve tried std::variant. It looks promising but unnecessarily complicated for our purposes. This is because we first have to figure out the type of std::variant (e.g. circle), and then cast it to the base type pointer (in our example: object*). The base type already has all the information that is needed, so we don’t need this intermediate cast.
So I wrote my own implementation called polymorphic_array. The idea is simple: we specify the types we want to save in the polymorphic_array as template parameters. The polymorphic_array works similar to the regular std::vector, it grows when there is no more space and you can append the elements at the end.
So, this is how it would look like for the previous case:
polymorphic_vector<object, circle, rectangle, line, monster> v;
v.emplace_back<circle>(point(20, 20), 10);
v.emplace_back<line>(point(0, 0), point(10, 10));
v.emplace_back<rectangle>(point(0, 0), point(10, 10));
for (int i = 0; i < arr_len * 4; i++) {
v.get(i)->draw(b);
}
Internally, polymorphic_array figures out the biggest type based on the template list and allocates enough space to hold any of the specified type in a single element of the array. The critical method of the polymorphic_array is polymorphic_array::get(int index) which returns the i-th element of the array as a base class pointer.
Our polymorphic_vector::get() returns a type object* (first template in the type). The biggest challenge when implementing is the conversion from type X* (rectangle, line, etc) to object*. During the conversion, the value of the pointer might change. We have the information about the underlying type only when the object is created (for example, in emplace_back method). Exactly then we need to perform the conversion from X* to object* and save the pointer, so the method get() can return the correct pointer.
So far, so good. The two implementations are very similar, except for a few differences that make polymorphic_vector easier to use. In terms of performance, here are the numbers:
std::vector<std::variant<...>> | polymorphic_array<...> | |
draw() runtime | 2789 ms | 2661 ms |
get_id() runtime | 482 ms | 415 ms |
get_id2() runtime | 424 ms | 397 ms |
Array of values: DOD arrays
In the game development, where the performance is crucial, there is a program optimization approach that revolves around performance called data-oriented design. The approach is very interesting, and I definitely plan to investigate it and write about it in the future.
One of the guidelines given there is not to use virtual functions, but instead to have a separate container for each derived class. This approach does away with polymorphism, but since we are in pursuit of performance, it is an idea definitely worth investigating. C++ template mechanism can be used to avoid code duplication since we cannot use polymorphism.
std::vector<circle> v1;
std::vector<line> v2;
std::vector<rectangle> v3;
for (int i = 0; i < arr_len; i++) {
v1.emplace_back(point(20, 20), 10);
v2.emplace_back(point(0, 0), point(10, 10));
v3.emplace_back(point(0, 0), point(10, 10));
}
for (int i = 0; i < arr_len; i++) {
v1[i].draw(b);
}
for (int i = 0; i < arr_len; i++) {
v2[i].draw(b);
}
for (int i = 0; i < arr_len; i++) {
v3[i].draw(b);
}
As we will see later, in all our measurements the DOD arrays are the fastest. And why? One of the reasons is the smallest amount of cache misses, the other is inlining. With DOD arrays the function address is known at compile time. The compiler can inline it. The cost of the call is gone. From that point on, it can do various compiler optimizations on it. An example, since the call of the function is inside loop, it can compile the vectorized version of the loop which uses special SIMD instructions of the processor for better speed. This is not possible with polymorphic function calls.
As far as memory consumption is concerned, this is the best solution. As far as speed is concerned, this is also the best solution. As far as flexibility is concerned, this is the worst solution. But performance is always about making compromises, and sometimes this might be the compromise you are willing to make.
The numbers
So we gave four implementations of our polymorphic container, but we didn’t compare them to one another. Let’s first compare the runtimes in the optimal case, when all arrays are sorted by object type. Additionally, pointer array points to neighboring chunks in memory.
| Method | Pointer array | Variant array | Variant visitor array | Polymorphic array | DOD array |
|---|---|---|---|---|---|
draw() runtime | 6139 ms | 6347 ms | 5674 ms | 6075 ms | 5579 ms |
get_id() runtime | 685 ms | 855 ms | 693 ms | 753 ms | 472 ms |
get_id2() runtime | 472 ms | 589 ms | 654 ms | 532 ms | 377 ms |
As you can see, DOD array is the fastest, but this is not unexpected since it doesn’t do any runtime dispatching. For long-running virtual function draw(), the versions of the function that dispatch using virtual functions (pointer array, variant array and polymorphic array) are about 10% slower than those that do not.
For small virtual and non-virtual functions, we definitely see the cost of virtual functions, even for DOD array!
Let’s shuffle the array!
In the previous code, we investigated an ideal case, where the arrays are sorted and everything is nicely and neatly packed in the memory. But, most of the time, this will not be the case. Let’s investigate a worst-case scenario; your case can be put somewhere in the middle between the best and the worst.
We use std::random_shuffle to shuffle all the arrays. Now objects are not more sorted properly, there will be many more cache misses and more branch prediction misses. Here is how the numbers compare for best and worst cases:
What stands out are pointer arrays. When the pointed chunks are unsorted, this is a disaster for performance. The unsorted array is more than three and a half times slower!
The variant array and variant visitor array are around 20% slower, and this is due to branch prediction misses. Polymorphic arrays and DOD arrays don’t have the penalty of data cache misprediction or branch misprediction.
Similar numbers can be seen for the other two functions get_id() (short, virtual) and get_id2() (short, non-virtual):
Here you can see that pointer array scales really badly. Because of many data-cache misses, performance is more than 10 times slower. Variant arrays don’t have data cache mispredictions, but they do suffer from branch mispredictions. The worse case is two and a half times slower than the best case.
DOD arrays and polymorphic arrays scale well. But DOD arrays are still the fastest, they are roughly 20% faster than polymorphic_array.
Final Words
Runtime polymorphism always comes with a price. If the function address is not known at compile-time, some kind of calculation must be done for each call at runtime. And a price in terms of the performance has to be paid.
The bigger problem with the default way C++ constructs an array of polymorphic objects (using pointers) is the possibility of many data cache misses and huge slowdowns due to it. Polymorphic arrays and variant arrays deal with this successfully, albeit with the price of increased memory consumption.2 But if the speed is what you need and you are not willing to sacrifice flexibility, this is the way to go.
Variant arrays (in our case std::variant with std::visitor) don’t have the problem with data cache misses, but they do have problem with branch prediction misses. And this makes them slow in the case the objects in the array are not sorted by type.
Polymorphic array scales well with regards to branch prediction misses and data cache misses. It is a good solution if you need both speed and flexibility.
DOD arrays are actually not polymorphic, but they can be used to provide flexibility in case the performance is crucial. They use minimal memory, have the best data-cache hit rate and branch prediction rate. Usage is a bit more complicated, but if the speed is crucial, this is the right path.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Hi,
You are misusing std::variant in two ways and that puts it in a bad light.
First, you should generally not rely on holds_alternative and std::get, but instead call the std::visit function which you can pass a generic lambda and avoid the whole boilerplate you are showing as a drawback.
Second, you still rely on virtual functions and classes derived from the same base class – this is a cost made unnecessary by std::variant. Instead of casting to base, you should rather directly call the draw function through std::visit, which will enable inlining all those calls. The draw function should not be virtual.
Without these changes you are penalizing the variant solution.
You are right! I learned about the visitor two weeks after I wrote the article.
I will need to redo the experiment with the visitor and add it here. But visitor syntax is nasty. Thanks for the feedback!
Ugh, sorry for probably a dumb question, but I’ve been trying to reason about your polymorphic array for more than an hour and I probably don’t have enough qualification to properly understand it myself.
Does it benefit from custom function that solves the need to search for where the vtable is located from element to element because offsets per element are inside a separate vector , and are always accessible through get() for prefetching and optimal execution?
The hardware prefetcher that is inside CPU can figure out that we are accessing our data sequentially, and can prefetch data from memory before we even need it. Polymorphic array exploits exactly this. It lays out data in memory sequentially, the hardware prefetcher figures this out, and iterating through this array is typically faster.
But then, how is that different from using custom allocator and just allocating sequential chunks for our polymorphic classes?
If you just allocate everything at once using a custom allocator, there is no difference. But if you happen to remove, shuffle, sort or do any operation on the array that changes the order of the pointers, then you will start to see performance drops.
Hi, very good article.
Can you describe why polymorphic arrays don’t suffer from branch misperception (when they are shuffled)?
Also, you say that get_id2() is non-virtual. I’d like to make sure you mean non-virtual method of the Base class. In that case, the extra cost of variant is that it isn’t ‘aware’ that the function isn’t virtual, and if instead of [](auto&s){return s.get_id2();} you wrote [](Base&s){return s.get_id2();} you’d gain the performance of polymorphic array?
If that’s the case – it means that variants can give good performance – BUT (as you mentioned) it’s not intuitive, and hopefully future language support (pattern matching) might potentially unlock that performance potential with more intuitive code.
Polymorphic arrays dispatch function using what is basically a lookup table. The hardware has to speculate on the destination of the branch. In contrast, std::variant basically use a chain of nested ifs to decide on which function to call (at least that is my understanding). So, there is a chain of branches. The hardware, instead of doing one prediction (as in the case of a lookup table), does several of them. I wouldn’t be surprised std::variant not scaling, i.e. performance is getting worse and worse with more types used for the variant.
As far as your proposition to use [](Base&s){return s.get_id2();}, in theory, it might work but in practice, I am not sure if it would compile or work as expected (performance wise).
I wrote another blog post about virtual functions, there I give an example of
multivector, which is a wrapper for std::vector where each type gets its own vector. That data structure uses memory better (since each type is stored in a special array), the code is very readable (e.g. multivector.for_each([&] (auto& o) { o.draw(b); }), but you cannot sort the elements in the multivector, only in individual vectors.Thanks a lot for the detailed reply.
The performance of std::visit is enforced by the c++ standard to be constant time (when given a single variant argument, no matter how many alternatives the variant has) – and thus it’s typically implemented as a jump-table.
If anyone’s interested, in the last few minutes of my talk about variants, I actually dive a little into this, and show that in some cases the if-else approach might have advantages because it’s easier for compilers to inline through them. That’s mostly useful in the unshuffled case, though – when things are relatively predictable.
Post a link to the talk, I am interested.
https://youtu.be/hEoeVAfslmg
In the “Array of values: std::variant with std::visit” section, you don’t need overloaded because the single lambda you’re passing to visit is generic. You only need overloaded if you want an easy way to combine multiple lambdas into one visitor. In this case you don’t, so really there’s no boilerplate required. Get rid of overloaded and I think the result is pretty clean and idiomatic.
Can you please provide an example?
Sure, simply remove the “overloaded” helper class from the example in that section. Here it is with mock types / draw functions to show that it works: https://godbolt.org/z/cqEn8EYnM
Identical assembly produced, thanks, will do!
Does it matter that the shuffle routine in polymorphic_vector.h does not use std::random_shuffle?
It doesn’t matter.
My error. It does matter. It must call random_shuffle. I am sorry!
I wonder why the polymophic_vector doesn’t suffer any penalty of shuffle but it turned out the shuffle method in polymorphic_vector.h doesn’t shuffle at all.
It supposed to shuffle the indexes but it doesn’t.
As I tested, if shuffled correctly, polymophic_vector slows down as same as the variant.
Yes, you are right! This is an important discovery, the call to std::random_shuffle is missing. I will need to update the post. Thanks!
// clang++ poly_value_any.cpp -std=c++17
// found on this website https://www.fluentcpp.com/2021/01/29/inheritance-without-pointers/
#include
#include
#include
template class Polyval
{
public:
template
Polyval(ConcreteType &&object)
: storage{std::forward(object)},
getter{[](std::any &storage) -> Interface & { return std::any_cast(storage); }}
{
}
Interface *operator->()
{
return &getter(storage);
}
private:
std::any storage;
Interface &(*getter)(std::any &);
};
struct ICar
{
virtual std::string alarm() const = 0;
virtual ~ICar() = default;
};
struct Ferrari : ICar
{
std::string alarm() const override
{
return std::string{“Ferrari”};
}
};
struct Lada : ICar
{
std::string alarm() const override
{
return std::string{“Lada”};
}
};
struct Nocar : ICar
{
std::string alarm() const override
{
return std::string{“NO CAR”};
}
};
struct Garage
{
template auto make_car()
{
return Polyval{T{}};
}
void set_lada()
{
mycar_ = make_car();
}
void set_ferrari()
{
mycar_ = make_car();
}
std::string beep()
{
return mycar_->alarm();
}
// holder for any subtype of ICar
Polyval mycar_{Nocar{}};
};
int main()
{
Garage mygarage;
Garage mygarage2;
mygarage.set_lada();
mygarage2.set_ferrari();
std::cout << mygarage.beep() << std::endl;
std::cout << mygarage2.beep() << std::endl;
// here no need virtual clone() !!!
mygarage2 = mygarage;
std::cout << mygarage.beep() << std::endl;
std::cout << mygarage2.beep() << std::endl;
return 0;
}
I think `std::any` internally has a pointer, so this solution is again dereferencing pointers and has a potential for a large number of cache misses.