| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
Summary: If your program uses dynamic memory, its speed will depend on allocation time but also on memory access time. Here we investigate how memory access time depends on the memory layout of your data structure. We also investigate ways to speed up your program by laying out your data structure optimally.
In the previous post we talked about how to make memory allocation and deallocation fast in your program. But allocations are only one part of the story of dynamic memory. The other part which is at least equally important is memory access time.
When you first do computer courses, you learn about dynamic memory (a.k.a. heap) and allocation and deallocation. The idea is simple: you need a memory chunk, you ask it from the allocator. You don’t need a memory chunk, you return it to the allocator. However, this simplified view doesn’t take into account the underlying hardware memory subsystems. And these can make your program run fast if used correctly, or slow if not. Allow me to explain:
Modern processors are way-way faster than the main memory and they have to wait for the data from the main memory. To remedy this, hardware engineers have come up with a trick. They add a small memory called cache memory between the processor and the operating memory. Cache memory is super fast, but tiny compared to the main memory. Every time the processor wants to access the operating memory, first it checks if the data it needs is in the cache. If it is, the processor gets it very fast (typically 3 cycles for L1 cache, 15 cycles for L2 cache), otherwise, it needs to wait for the data to be fetched from the main memory (typically 200-300 cycles).
Humans use the principle of caching in real-life all the time. For example, we keep the books we are currently using on our desks and the ones that we use on the shelf. If there is a book we don’t need anymore, we will return it to the shelf to free space on the desk for other books.
There are several types of cache memories in modern computers, but two of them are interesting when it comes to dynamic memory access. One is called data cache memory and the other is called TLB cache memory.
Data Cache Memory
Instructions are reading and writing data, and the purpose of data cache memory is to speed this up. I wrote extensively about the data cache memory in a post about data cache optimizations, and there is a section on how data cache memory works there.
But the summary is like this: memory access to the data will be fast if the data is in the cache memory. When it comes to dynamic memory, we can increase the chances of it being in the cache memory if we lay-out our data structures cleverly in the operating memory. Here is an example to illustrate this:
A program creates a binary search tree (BST) by allocating 100,000 chunks from the memory allocator using new/malloc, and each chunk is 48 bytes in size. If you are not familiar with binary search trees, they look something like this:

How do we look up a value in the BST? We compare the search value with the root of the tree, if it is smaller, we go left, if it is larger, we go right. We repeat the process until we find our value or reach the last node.
When you are creating your BST, you allocate memory chunks using malloc (or new) for every node in your tree. This means you will call allocate 100,000 times. And the allocator will return 100,000 memory chunks which you know nothing about. They can be close to one another in memory, or they can be scattered all around the memory, you simply can’t know.
If the allocator would allocate chunks in a certain pattern, this would increase the data cache hit rate and make your program run faster. For example:
- 100,000 allocations take 4,800,000 bytes, i.e. 4.58 MB. For the best performance, keep all the chunks in a block of the smallest possible size. If you keep all the allocation in the block of 4.58MB you can expect better caching behavior compared to when keeping all the allocations in a block of size 10MB, 100MB etc.
- Second thing is to understand how your data structure is logically accessed and to lay out memory chunks in a similar way. In case of our binary tree, we are traversing the tree by going from one node to another looking for a value. But upon closer investigation, you can see that we are always accessing nodes in the same order: node on level 1, followed by a node on level 2 etc. So a good idea would be to lay-out memory chunks in the same order as they are accessed: level 1 memory chunk should be followed by level 2 memory chunk etc.
If you are allocating memory chunks by calling regular malloc/new, you don’t have any control over how memory chunks are laid out in memory. So you will need to add a custom allocator to your data structure that allocates from a dedicated memory block. This increases the likelihood of the memory being in the data cache and the speed of your program. Tip to use this type of allocator applies to standard containers (std::map, std::list) too. But note that memory consumption may go up as well.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
TLB Cache Memory
Almost all modern CPUs provide virtual memory. Userspace programs never see the actual physical memory addresses, instead, there is a piece of hardware called Memory Management Unit (MMU) that translates virtual addresses to physical addresses.
The operating system typically allocates memory in pages of 4 kB and virtual to physical memory translation is done on the page level. For each allocated virtual page there is a corresponding physical page in the main memory.

Page translation must be very fast because it is done both for instructions and data. Even a minor delay can have a huge performance impact. To speed things up, part of MMU is Translation Lookaside Buffer (TLB). TLB is a small and very fast cache memory that translates virtual addresses to physical addresses.
To make TLB fast, the hardware designers have limited its size. For example, on my desktop system, level 1 TLB has only 64 entries, which means that at one point it can do a fast translation for at most 256kB of memory. Level 2 TLB has 1536 entries, which means that at one point it can do a translation for most 6MB of memory.
Normally, the problems with TLB cache misses are rare in those programs with not too big data sets (less than a few megabytes ) or where the data is accessed sequentially. However, as the working set grows, so do the TLB cache misses.
All the advice given to decrease the amount of cache misses that we gave in the previous section also apply here: (1) keep your data compact in memory and (2) don’t jump around the memory a lot should be enough to keep TLB cache miss rate low. However, in case of a really large working set even this won’t help.
But do not despair, there are good news as well. Many operating systems support large page sizes. Instead of the default page size of 4 kB, they support page sizes of 2 MB and 1 GB. Here are the results for my test program:
| Execution time | TLB cache miss rate | Page faults | |
| Memory pages 4 KB | 9236 ms | 2.23% | 78508 |
| Memory pages 2 MB | 6837 ms | 0.01% | 20029 |
As you can see, the speed improvements might be well worth it. Setting up large memory pages is a bit involved, you can find the instructions on how to do it here.
Page faults
On Linux, your program typically asks for memory from the operating system using mmap system call. Linux returns a pointer to the block, but no actual allocation is done. Only when your program first writes to a memory location, the operating system will allocate one page that corresponds to the memory location being written to. So if your program allocates a memory block of 2 MB, but writes only to a first few bytes of the block, only 4 kB (one single page) will be actually allocated.
The good thing about this behavior is that it saves memory. If a program allocates a huge block of memory for one reason or another, but never uses it, no memory will be allocated. But when it eventually writes into it, the instruction will cause pagefault because there is no mapping between a virtual block and its physical block. The operating system takes over and creates a mapping by allocating a block in physical memory. Now the instruction that caused the pagefault can resume.
Page allocation takes time and generally you will want to avoid it. However, it is only done once and unless you have a system with a low amount of operating memory2, you will not have to pay to price of page allocation for every memory access.
To keep page allocation minimal, the same tips apply as to how to keep the data cache misses and TLB cache misses low. Don’t let the pages go wasted, utilize as much as you can. If speed is important, opt for large pages. On Linux, mmap system call has a parameter MAP_POPULATE which will allocate all the memory upfront so no pagefaults happen later.
In practice: how to design your data structure and your allocator
If you replace the global system allocator, as we described in the previous post, your program will probably get quicker and more responsive if it is memory intensive. However, if access speed for one particular data structure is vital, you will want to take the allocation for that data structure into your own hands.
To lay out memory chunks in the best possible way for your data structure, you will need to use the custom allocator. And the data structure must be aware of how the allocator allocates chunks. In this section we will talk about how to write your custom allocator and your data structure for maximum performance. We are making a few assumptions in this section:
- You are holding your data in a data structure. It can be a linked list, any kind of tree, hash map or something else. But the most important thing is that all memory chunks are allocated to a single data structure.3
- The most common operation you want to do in the data structure is element access. But occasionally you also want to add or remove the elements in the data structure as well. Structures that change rarely are much easier to optimize for memory access than those that change a lot.
Access pattern and data structure layout
Normally, a stream of keys is coming from somewhere and you are using the keys from the stream to look up the data in your data structure. Let us assume that all the keys from the input are equally probable. We want to optimize the average access case for that particular key distribution.
Let’s take as an example a binary search tree with unsigned integers. When traversing a binary tree, we know that the element on the level 0 is accessed every time, the element on the level 1 is accessed every second time, the element on the level 2 is accessed every fourth time etc.

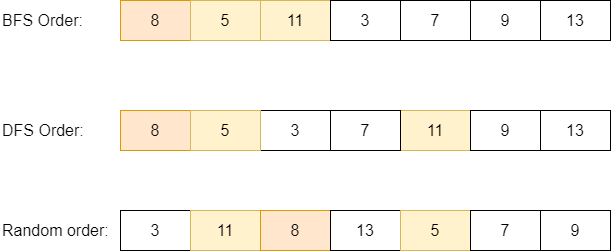
Now, the question is how to lay out our tree in memory for optimal access? We investigated two approaches than naturally come to mind, one is to lay it out level by level (Breadth-first search (BFS) order): first, node on level 1, then nodes on level 2, then nodes on level 3 etc.
The second approach is to lay out the tree in Depth-first search (DFS) order: we allocate memory chunks for our tree recursively. We allocate memory for the current node, then we allocate memory recursively for the left subtree and then we allocate memory recursively for the right subtree. This explanation might seem complicated, but the animation below illustrates it better.

For the case of BFS layout, the nodes on the same level will be close to one another in memory. For the case of DFS layout, the node directly on the left of the current node will be close in memory. We know that if two memory chunks are close to one another, we increase the data cache hit rate. So which approach is better?
We did a small experiment. To illustrate the difference in speed, we created two binary trees. They both are completely the same, but are laid out in memory differently. One has BFS layout, the other has DFS layout. The size of the tree is 10 M elements, and the size of a single chunk is 24 bytes, so the whole tree took about 228 MB of memory. We measured how much time does it take to perform 10 M accesses.
| BFS Layout | DFS Layout | |
| Runtime | 12546 ms | 9084 ms |
| L1 data cache miss rate5 | 25.4 % | 18.6 % |
| LLC data cache miss rate6 | 47 % | 44.3 % |
As you can see, DFS layout clearly dominates. It is difficult to experimentally confirm the reason, but we think it’s the following. The memory chunk of the left child node is directly after the parent node. In case of random access, taking the left pointer or the right pointer has the same probability. If we take the left pointer, there is the chance that this data is already in the data cache. Hence the speed difference.
In case the probabilities for the input keys were skewed (taking the right pointer has higher probability), we could expect to see BFS layout to perform better.
What happens if there are few keys in the input stream that appear much more often than other keys? In that case you could consider adding a small software cache, a small and fast hash map just for those cases. A hash map with the size of 64 entries has a really fast hash function (modulo by 64 is implemented as shifting), it will probably always be in the data cache since it is small and you don’t need to take care of collisions since the full data is in BST.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
The custom allocator
Allocators typically have very simple interfaces consisting of allocate and deallocate functions. When your program requests a chunk from the allocator, it never knows what kind of chunk will it get. And as we’ve seen, memory chunk layout is important for access speed.
For the optimum performance, you want to have a custom allocator that is specific to your data structure and that will give certain guarantees. For example, if you call allocate two times in the row you would expect to get two neighboring memory addresses.
If your data structure is mostly static (after initial creation, you don’t change it or change it rarely), you don’t need to implement the deallocate functions. When the whole data structure is destroyed, you can release all the memory related to it in one go.
However, if the data structure changes a lot, your allocator should implement deallocate function as well. Otherwise, your system might waste a lot of memory. And when you implemented deallocate, that nice property of your allocate that two consecutive calls to allocate return neighboring addresses goes away. But having a custom allocator is still better, because the allocator will reuse old blocks, and these are closer in memory to already allocated blocks. And the custom allocator is simpler and faster than a general-purpose allocator.
To measure the effectiveness of the allocator, we took the binary tree from the previous section and tried it with the following allocators:
- Optimal allocator: allocates memory chunks consecutively.
- Nonoptimal allocator: allocated memory chunks randomly in memory (there is space of 50 chunks between two allocations so that cache memories becomes ineffective).
- Builtin allocator: standard
std::allocator.
Here are the numbers:
| Optimal allocator | Nonoptimal allocator | Builtin allocator | |
| Runtime | 9135 ms | 16316 ms | 10585 ms |
| L1 cache miss rate | 18.6 % | 29.07% | 21.22 % |
| LLC cache miss rate | 44.5 % | 56.2 % | 33.5% |
Optimal allocator is the best, but builtin allocator is not that bad. But please bear in mind that this is a testing environment, in real life builtin allocator can fare worse due to its internal fragmentation.
Data structure properties
Another way to increase the data cache hit rate is to decrease the size of the memory chunk. Memory chunk typically consists of useful data and data structure internal data. Decreasing any of them will improve the data cache hit rate and speed of access.
Data structure internal data often involves pointers. To decrease pointer size, there are a few tricks but they are not portable. On 64 bit systems, pointer size is 8 bytes. However, only 6 bytes are actually used. If you have a pair of pointers (which is typical for tree-like data structures), you can store their values like this:
template typename<T>
struct pointer_pair {
uint64_t m_left: 48;
uint64_t m_right: 48;
};Size of this struct is 12 bytes.
If your program doesn’t consume a lot of memory and you are running it on x86-64 architecture, you can recompile it with for x86 architecture and gain some speed. Pointers on this architecture are 32-bit wide and this will make the data structure smaller and increase the data cache hit rate. Here are the numbers:
| 64-bit version | 32-bit version | |
| Runtime | 9135 ms | 7752 ms |
| L1 cache miss rate | 18.6 % | 15.27% |
| LLC cache miss rate | 44.5 % | 46.41% |
The other thing that you could do is to decrease the size of the actual data. Imagine that you are keeping information about the players in an online game in a data structure. Each player has a unique ID, name, score etc. You are indexing your data structure by ID, so keep the ID only in the data structure and a pointer to the rest of the data outside. This increases the data cache hit rate.
Modifying data structure
Everything said up until now mostly has an inherent assumption that you don’t modify your data structure that much. But what happens if you do modify it?
When memory chunks are removed from the data structure and new memory chunks are created, the optimal chunk memory layout slowly deteriorates. Accessing your data structure gets slower and slower. There are a few things to remedy this, or at least to slow down the deterioration. Let’s take a binary search tree as an example, but you can apply similar techniques to other data structures as well:
One thing you could do is not to remove the nodes when the value is removed from the tree. In case of a balanced binary tree, the node that will be left after removal will be a leaf node. Keep them there for some time, later when a new value is inserted you will not need to do the memory allocation and the memory layout will be preserved.
If addition and removal happen too often, the memory layout will bit by bit become less and less optimal. What you could do is to perform defragmentation. You basically create a new data structure with an optimal layout and copy everything from the old data structure. Alternatively, you could perform defragmentation in place, but this will often be more complicated. Of course, defragmentation can be slow but if the access speed is important and you could do it.
Final Words
I think that we’ve given enough evidence on how properly tuned data structure can beat a default one by a factor of two at least. When speed is important, fine-tuning can make all the difference.
If this topic is important to you, have a look at EA standard template library, a replacement for standard template library where data structures and algorithms are optimized for speed. Many of the ideas presented there can be applicable to your circumstances, even if you are not using the library itself.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Further Read
ITHare.com: C++ Performance: Common Wisdoms and Common “Wisdoms”
ITHare.com: C++ for Games: Performance. Allocations and Data Locality
ITHare.com: Size Matters – Is 64-bit App Always Better?
EA Standard C++ library: Best Practices
Urlich Drepper: What every programmer needs to know about memory
- Taken from https://scoutapm.com/blog/understanding-page-faults-and-memory-swap-in-outs-when-should-you-worry [↩]
- If your system is running low on memory, the operating system can decide to swap some less used pages from the operating memory to the hard drive. Next time you want to access the data in the swapped-out page, you will pay a huge performance penalty because OS has to load it back from the hard drive to the operating memory. [↩]
- The other possibility would be to allocate memory chunks and use them for communication between different components, but we will not consider this case right now. [↩]
- Source: https://en.wikipedia.org/wiki/File:Depth-First-Search.gif [↩]
- Cache miss rate for L1 cache, small but fast cache that is accessed first. [↩]
- LLC stands for Last Level Cache, these misses are most expensive [↩]
{kind=link}