| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
Linked lists are celebrity data structures of software development. They are celebrities because every engineer has had something to do with them in one part of their career. They are used in many places: from low-level memory management in operating systems up to data wrangling and data filtering in machine learning.
They promise a lot: if the list has n elements, you can traverse it in O(n) time, and you can insert into it and remove from it in constant time. In contrast to vectors, where insertion at a random place and removal from a random place has a O(n) complexity, they seem like perfect data structures when you need to filter data, reorganize data, append data in random places, etc.
But, under all the pretty promises, things don’t look that shiny. Linked lists are data structures that are notorious for bad hardware resource usage, particularly bad usage of the memory subsystem. Why?
Why are linked lists slow?
We wrote several times in this block, but we are restating it again. On modern hardware, the bottleneck is often the memory subsystem. CPU is fast but the memory isn’t. What this means is that between the request made to the memory subsystem and the response, the CPU can wait up to 300 cycles. For this reason, CPUs contain a component called a prefetcher that can figure out the access pattern of your program and prefetch data before the data actually becomes needed.
Linked lists suffer from slowdowns because, while traversing the linked list, your program is following the next pointer and jumps around the memory in an unpredictable fashion. In arrays, the memory access is predictable: if CPU is processing an array of integers and it is currently processing an element at address X, the next element will be at address X + sizeof(int). In linked lists, the address of the next element will be known only after the next pointer is dereferenced. There is no pattern to memory access, and the CPU has to pay the full price of data cache misses.
Additionally, the data from the memory is fetched typically in blocks of 64 bytes. Arrays take advantage of this, because if the block doesn’t belong to the currently processed element, it belongs to the next element. On the contrary, one part of the 64 bytes of data that is fetched from the memory will belong to the current node, but the other part can belong to some completely irrelevant component and the rest of the block is wasted data transfer.
There is additional reason why linked lists are slow, and this is low instruction level parallelism. While traversing a linked list, the CPU doesn’t have a lot of work to do because it cannot start processing the next node until it has finished loading the current node. Instruction level parallelism will not be the topic of this post, we talk about it here.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
So, how does linked list performance depends on memory layout?
When someone tries to explain the concept of a linked list to you, they do it by using the following chart:

A linked list consists of nodes. Each node contains a value and a pointer to the next node. The last node in the list points to a termination node, which is typically a nullptr. In this example, the linked list consists of three nodes, with corresponding values 12, 99 and 37.
From the performance perspective, however, this chart is incomplete. All nodes have their places in memory, and the memory layout is crucial for performance. Here are three different layouts of the same linked list:

The first layout (we call random layout)is the layout you might come up with if your system is allocating and deallocating nodes for a long period of time. It is the least efficient: the nodes are not close to one another in memory and, while iterating through the linked list, the access pattern is completely unpredictable.
The second layout (we call it compact layout) is better: the nodes are close to one another in memory. The memory access pattern is still unpredictable, but the fact that the nodes are close to one another increases the chance that the next node is in CPU’s data cache and therefore increases performance.
The third layout (perfect layout)is the best. While iterating through the list, the program is accessing neighboring memory locations. The data prefetcher can figure out the memory access pattern and can preload the data so that the data is available before the CPU even needs it.
If you are using a simple linked list, e.g. std::list, you don’t have any control of the memory layout. It might happen that for a small test program std::list is very fast, but in a production environment it is much slower. The reason is simple: in the small testing environment, the system allocator can return neighboring memory chunks thus creating a perfect memory layout for std::list. In a production environment, however, this is often not possible as memory needs to be reused, so the allocator will return chunks of memory that were used earlier.
Let’s compare linked list performance with respect to the memory layout. For this test, we will use linked lists of doubles, and we will sum up all the values in the list. We pick three sizes of linked lists: small (128 doubles), medium (1M doubles) and large (64M doubles). We iterate each linked list enough times so that in the end we iterated through 64M values.
Here are the numbers for different linked list sizes:
| Linked List Size | Random Memory Layout | Compact Memory Layout | Perfect Memory Layout |
|---|---|---|---|
| Small (128 doubles) Runtime: L3 Data Cache Request Rate: L3 Data Cache Miss Rate: Data Transferred from Memory: | 0.08 s ~ 0% ~ 0% 0.26 GB | 0.07 s ~0% ~0% 0.25 GB | 0.07 s ~0% ~0% 0.25 GB |
| Medium (1M doubles) Runtime: L3 Data Cache Request Rate: L3 Data Cache Miss Rate: Data Transferred from Memory: | 8.2 s 22 % 92 % 21.7 GB | 6 s 23 % 68 % 13 GB | 0.12 s 1 % 89 % 1.25 GB |
| Large (64 M doubles) Runtime: L3 Data Cache Request Rate: L3 Data Cache Miss Rate: Data Transferred from Memory: | 15 s 24 % 99 % 34.2 GB | 9.7 s 24 % 99 % 25.2 GB | 0.12 s 1 % 99 % 1.36 GB |
Let’s analyze the numbers in the table. For a small linked list, the memory layout is not that important. We can reasonably expect that the whole linked list fits the L1 cache. You can see that the data transferred from the memory remains constant regardless of the layout, which again confirms our hypothesis that the data set fits the data cache. The number of requests made to the L3 cache is almost zero as well.
For medium and large linked lists, the memory layout becomes much more important. Whereas the time needed to traverse the linked list with perfect memory layout remains stable at around 0.12 s, the numbers for two other memory layouts explode! The random memory layout is 68 times slower for the medium data set and 125 times slower for the large data set. The linked list with a compact memory layout, even though a bit better, is still much slower than the linked list with a perfect memory layout.
We see that the worse the layout, the amount of the data transferred from the main memory becomes larger. This is expected because of the block organization of the data caches: we load 64 bytes of data from the memory, even though we are using only 16 bytes.
Note that for the large linked list, the L3 data cache miss rate is 99%. This means that the L3 cache is useless for the data set of this size.
IMPORTANT NOTE: As you have seen, the performance of the linked list depends a lot on its memory layout. And the memory layout depends very much on the environment your program is running: the underlying memory allocator, other data structures in the program that allocate a lot of memory (other linked lists, trees or heap-allocated objects) and the way your program uses its linked lists (modifying linked list a lot ruins its good memory layout). So, the numbers we presented and we will present in the following section may look a lot different for your case.
How to make linked lists faster?
The question is if we can make linked lists faster? The answer is yes, but, as you will see later, the process of optimizing linked lists is not simple and straightforward.
The first conclusion that comes up naturally, is that for optimum performance of the linked list you need to strive for the perfect memory layout. The closer the memory layout is to the perfect layout, the faster will it run.
Second, notice that linked lists are very flexible data structures. You can add and remove elements at random locations with at O(1) complexity. All the pointers remain where they are regardless of the insertion and removal. It is very hard to think of a data structure that has similar properties.
In reality, much of the flexibility is not needed. For example:
- Unless you are holding pointers to the elements of the linked list in other data structures, you don’t need iterator stability.
- If you are filtering data, you want to be able to remove elements at any location, but you will always insert them at the beginning or the end.
- If you use linked list to keep a unsorted collection of objects, you don’t care at what location you want to insert your object. You only want to be able to insert and remove objects, and at the same time keep the memory consumption low. You can cheapily insert into vector, but when you remove from it, you will waste memory space.
- Your linked list can be special in some way, e.g. most of your linked lists can be really small. In that case you want to optimize for the common linked list size.
Most of the time you don’t need the full flexibility of a linked list, only some part of it. Although we will give ideas on how to speed up regular linked lists, many times you will want to specialize your linked list for your application as this will result in the greatest speedup.
Faster alternatives to linked lists
So how do we make linked lists faster? The first thing you need to understand is that, when iterating over a linked list, you can expect a data cache miss every time you move to the next element unless the memory layout is perfect. So, if you don’t need to iterate over the list, don’t do it.
Alternatively, maybe you need to iterate over the list, but you can iterate only over some part of the list. You can introduce skipping pointers (or skipping iterators), to skip over the elements in the list that you don’t need to access right now.

In the above example, we can use the skip field to skip over the element in the linked list we are not currently processing, but that we don’t wish to delete.
Linked lists with a shared allocator
One of the ways to increase the performance of linked lists is to use a custom iterator for your linked list. We talked about custom allocators in the previous post about allocation and performance, but the summary is the following: with a custom allocator, all the memory for the linked list nodes can be allocated from a dedicated block of memory. Because of this, the nodes that make the list are more compact in memory. This increases the data cache hit rate and TLB cache hit rate.
Standard STL containers, including std::list and stl::forward_list can be configured with a custom allocator. The process is really simple, and you can find an allocator online (e.g. moya allocator). The downside to this approach is that all the instances of the same type share the same allocator. For example, all instances of std::list<int, my_alloc> will share the same allocator. This approach is good if you have many small linked lists, but can be problematic if you have a few, but large linked lists.
Using a custom allocator typically results that the nodes of the list are more compact in memory, which corresponds to the compact layout we described earlier. But if you have many instances of the same list, they all will share the same allocator, and as a consequence, you should not expect that the consecutive nodes in the list are consecutive in memory.
Linked lists with a per-instance allocator
For larger linked lists it can pay off to have a separate instance allocator for each list. If the allocator returns consecutive chunks in memory, this will translate to consecutive nodes being at consecutive memory locations, which further results in an almost perfect ordering of nodes in memory and the performance comparable to those of vectors.
Unfortunately, STL doesn’t offer such data structures, so you will have to write them yourself or try to find implementations online.
Linked list backed by std::vector
We wrote an implementation of a linked list called jsl::vector_list that uses std::vector instead of an allocator for storage. The list allocates memory for its nodes from the elements of underlying std::vector. When a node is deleted, it is returned to the list of free nodes. This node can be later reused when new values are inserted into the list. Both the linked list with data, and the linked list with free nodes are stored in the same vector.
There are several advantages to this approach:
- It avoids calling the
allocatefor each insertion to the list anddeallocatefor each deletion from the list. std::vectorhandles memory allocation in a simple way.- The block of memory used for nodes is very compact, which increases data cache hit rate and TLB hit rate.
- Allocating from a single block of memory effectively avoids memory fragmentation. When the linked list is destroyed, the whole block of memory is returned back to the operating system.
- It uses indexes instead of pointers to point to the next item in the list, and indexes have smaller sizes. The node itself is smaller which increases data cache hit rate.
- If you create a list by inserting elements at the beginning or end, you are guaranteed to have the perfect ordering and the best performance.
- It offers
compactoperation which recreates the perfect ordering of nodes in the memory and can be called when the linked list becomes too fragmented. It also releases unused memory back to the operating system.
There are also some disadvantages:
- It uses more memory. If
std::vectorregrows at bad time, it can consume two times more memory than actually needed. - If many nodes are deleted from the list, many nodes can reside in the free nodes list but are actually unused. This increases memory consumption. In that case it pays off to perform the
compactoperation. - The iterators are not stable. When the vector regrows, the iterators get invalidated. But the indexes into the backing vector remain stable, so you can use them instead.
Since we implemented the data structures, we implemented a quick performance evaluation. We compared the performance of std::forward_list<int> and jsl::vector_list<int> for various operations. Please note that in this small test program std::forward_list will probably have a near perfect memory layout initially since it is the only data structure in the program that allocates memory.
Here are the numbers:
| Operation | std::forward_list runtime | jsl::vector_list runtime |
|---|---|---|
| (1) push_back 128 M integers | 2.9 seconds | 0.9 seconds |
| (2) erase every fifth element | 0.45 seconds | 0.2 seconds |
| (3) insert a new int at every third place | 1.2 seconds | 0.7 seconds |
| (4) traverse the whole list | 2.1 seconds | 0.4 seconds |
| (5) traverse after compact | – | 0.27 seconds |
std::forward_list and jsl::vector_listWe performed altogether five operations on our lists. At step 1 we inserted 128 M integers into both lists. The reason why std::forward_list is slower is probably because of the need to call malloc for each element of the list. Our jsl::vector_list doesn’t call malloc, so typically allocation is very fast.
The same applies for step 2: deleting from the std::forward_list is slower because it needs to call free for each element of the list. In step 3 we insert a new integer at every third place in the list. In step 4 we traverse both lists and compare the runtimes. Both lists suffer from slowdowns because of an imperfect memory layout, but jsl::vector_list suffers less since std::vector will keep the block of memory as compact as possible. Traversing the whole list is more than 5 times faster for the jsl::vector_list. After the layout of jsl::vector_list is made perfect again using compact, jsl::vector_list is more than 7 times faster.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Unrolled linked lists
Unrolled linked lists are another way of making linked lists faster. The main idea behind unrolled linked lists is to store more than one value in a single linked list node.
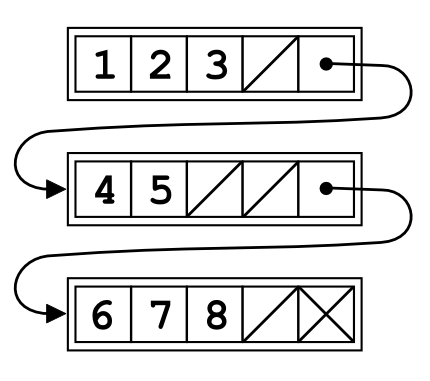
In the above example, the list stores 4 elements in a single node. The advantages of such solutions are:
- Better data cache usage. Using unrolled linked list increases the data cache hit rate, TLB cache hit rate and general performance.
- It avoids calls to the system allocator. Instead of having N calls for the simple linked list of size N, a unrolled linked list with a factor X makes N/X calls to the system allocator, which is significantly smaller.
There are also downsides:
- Depending on the implementation, they can use more memory than regular linked lists (this happens if a single node is not completely filled).
- Iteration is more complex. For a simple linked list, the iteration is just a pointer dereference. For an unrolled linked list, the iteration can be either pointer dereference (end of list), or an moving to the next value in the node (which is increment).
- Depending on the implementation, iterators might not be stable. To optimize for performance, some shuffling inside a single node might be needed when a new element is added to the list which can decrease performance.
We compared the performance of unrolled and regular linked lists in the earlier post about ways to make your program run faster by better using the data cache. Here are the numbers from the same post:
As you can see, the higher the number of values in the node, the better the performance. This is especially true if you are holding large data types as part of your list.
An unrolled linked lists implementation is available in the PLF C++ Library. It is a drop-in replacement for std::list, so it can be used with minimum changes to your code. The authors claim that their implementation is 293% faster than std::list when it comes to insertion, 57% faster when it comes to erasure and 17% faster when it comes to iteration.
Data filtering using linked lists
When doing data filtering, first you are filling your linked list with data, and then you are removing data that is not according to a certain criterion. Linked lists are also used for this, but the process can be optimized.
In this particular case ordering of values doesn’t change if we remove other values. If we use std::vector to store our data, we can get rid of the next pointer, saving some space but also increasing the data cache hit rate. We can store information about used and freed values in a bitset. Each bit in a bitset corresponds to a value: if the bit set the value is present, otherwise it is left out.
Similarly, for a linked list backed by a vector, we can perform a compact operation to get rid of the gaps and make the memory access more data cache-friendly, after we have performed a sufficient number of element removal.
We implemented jsl::filter_vector which is a data filtering list backed by a vector. It uses boost::dynamic_bitset to store information about free and occupied nodes. Here is the comparison of jsl::filter_vector and jsl::vector_list. Here are the numbers:
| Operation | std::list | jsl::filter_vector |
|---|---|---|
| (1) insert 256M integers | 6 s | 1.8 s |
| (2) traverse the whole list | 0.72 s | 0.66 s |
| (3) erase 4 out of 5 elements (leave every 5th) | 2.1 s | 0.92 s |
| (4) traverse the whole list | 0.73 s | 0.38 s |
| (5) traverse the whole list after compact | – | 0.12 s |
std::list and jsl::filter_vectorWe see a similar pattern as with jsl::vector_list. Insertion and deletions are slower because of the need to work with dynamic memory through the system allocator. After the insertion, the times needed to traverse the whole list is similar for both std::list and jsl::filter_vector.
After erasure, although we removed 80% of the element in the list, the time needed o traverse std::list didn’t change, and the time needed to traverse jsl::filter_vector was less than two times shorter. The real performance improvement happens after the compact operation on jsl::filter_vector. The runtime is now three times faster than the runtime before the compact.
The time needed to traverse jsl::filter_list of 256 M integers was originally 0.66 seconds. After we removed 80% of the elements, the runtime was 0.38 s, which is less than 2 times faster. But, after the compact operation, the runtime is 0.12 seconds, which is 5 times faster than the original. Only after restoring the perfect memory layout is the speedup (5x) as one would expect.
Unordered collection of objects
The game developers first had this problem: they have a collection of objects, but the ordering is not important. What is important is that you can quickly traverse the collection, you can quickly add an object and quickly erase it. A linked list might seem like a good solution to this problem, but requirements for game performance mean that a simple linked list doesn’t cut it.
So they developed a new data structure called colony that can be used to store a collection of unordered objects, with traversal, insertion and erasure complexities which are the same as those of linked lists. But colonies are much more data cache-friendly, because they internally use vectors.
Colonies allocate memory in blocks that can hold a fixed number of objects. When a new object is added to the colony, if there is no place available in any of the blocks, the colony will allocate a new memory block to hold the new object. When the object is deleted, its place is the memory block is freed and can be reused later, but colonies typically do not release memory back to the system except when the whole block of memory is free.

Iterators in the colonies are stable, i.e. once an object is added to the colony, its address will not change. This is important for gaming, where objects in different colonies can reference one another using pointers.
Colonies are currently in the process of being added to STL as std::colony (or std::hive). In the meantime, you can find colony implementation as plf::colony.
According to its authors, its performance is better than any std:: library container for unordered insertion, better than any std:: library container for erasure, and better than any std:: library container except for vector and dequeue.
Specializing your linked list
We gave here several interesting alternatives for a linked list, but in the end, the data pattern and data access pattern in your particular program will define what is best for you. When doing this, you should have the following guidelines in mind: (1) keeping the block of memory from which you allocate nodes as tight as possible and (2) making sure you are running through the memory sequentially should guarantee optimal performance.
Here are some examples where none of the raw approaches we presented would work:
- A program with many linked lists, 95% of the lists have 2 elements in them. In this case, the data cache misses would not come from iterating through the list, but from switching from linked list X to linked list X + 1. Here, the challenge is not packing a single list, but packing a large array of small linked lists.
- A program that filters data, but after the initial filling, 90% of the data is removed in the first pass. If we were to use data filtering using linked lists as we described earlier, the vector would be sparsely populated and we would be left with a vector that is no better than a simple linked list. One of the solutions would be, in the first filtering pass, to allocate another vector and copy only remaining elements to it. Then we get rid of the original vector. The data in the new vector is perfectly ordered, so we can expect good performance later.
- A text editor. Although it might seem like a good idea to keep the text the user is entering in a linked list of characters for easy modification, in reality it is never done like that. This would fragment the memory too much, also the
nextpointer would take unnecessarily too much space. Text editors employ a data structure called Gap buffer, which allow cheap insertion and removal clustered around the same location. Internally, gap buffers ressemble regular memory buffers, but the text they hold is split in two halfs: left and right. Between the halfs, there is a gap, and inserting data into the gap is very cheap. More on gap buffers on Wikipedia.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Conclusions
What are the takeaways of this post? The main takeaway is that the memory layout is tremendously important for achieving good performance. A perfect memory layout (where neighboring nodes are neighboring in elements) is almost as fast as a vector.
The second is that maintaining the perfect memory layout requires some development effort on the developer’s side, and also it requires some additional runtime cost on the program’s side. It might happen that these costs are too high and that the performance of an ordinary list is just enough. That is up to you as a developer to measure and decide.
Another important aspect of linked list performance is instruction level parallelism, which we talk about in this post.
Thanks for this post! Which tool did you use to capture the cache miss/request rates?
LIKWID
Thank you. I come across examples and tools for perf monitoring on Linux like likwid here. Wonder why not windows?
I don’t have any experience with Windows. There is probably a similar feature on Windows, though.
One can have std::list with per instance allocator using std::pmr::list introduced in C++17.
Of course then they’ll pay the price of the virtual calls for allocation/de-allocation unless the LTO doesn’t succeed de-virtualizing them but this is a different story.
I never personally used std::pmr::list, and would definitely be a good thing to test them here (if I have time I will add a section). However, my general feeling is that the virtual dispatch mechanism is an order of magnitude faster than a data cache miss. So, if using virtual dispatching fixes issues with data cache misses, I wholeheartedly would try that approach.
Very nice article! I like your approach.
Regarding the vector based list, you can simply link the free nodes together instead of storing them in another vector. This way you have a single vector with two linkedlists inside, one with used nodes and another with free nodes that you can use at O(1) cost when you need a node.
I didn’t mention storing the free nodes in another vector, they are stored exactly as you are describing. I will amend the post to make it more clear.
Memory prefetching doesn’t work like that. For each process, there is a register that points to the next place in memory where the next machine instruction is stored. Machine instructions are short, even with their operands (parameters). So, say a 128-bit data bus can pull back a number of instructions at a time, which means fewer memory calls are required if the next instruction is not a jump to some other memory location. Even in calling memory for a linked list, a typically sized linked list element may well fit within that data bus or close to it. There is no reason a consecutive array of fixed width elements would be any different. Linked lists will generally require less memory to be pulled, in the first place… and no reallocations (very expensive operation) of memory segments–just new ones.
If prefetching meant more calls directly ahead in memory that that would slow down all software because machine language jumps happen all over the place.
On the other hand, you could make interlinked linked lists. Often my elements in a linked list are of different sizes. If there is a small finite set of distinct sizes then you could create one array for each and have them link between each other, as needed. This could be quick. There is no penalty for reaching farther in memory except where paging is required (depending).
I am trying to understand your answer. The post talks about data prefetching, but your comment implies instruction prefetching, which is a different concept solving a different problem. What is “calling memory”. You say “typically sized linked list element may well fit withing that data bus”, but data is not stored in the data bus, the data is transferred using the data bus. Sorry, but you are not expressing your ideas clearly and I don’t understand what is the problem.