
| Master software performance in just 16 hours! Join our Software Optimization for the Memory Subsystem Workshop taking place from May 18th to May 21st. Click here to express interest or register. |
In C++ courses held at the universities, you will often hear that virtual functions come with a performance penalty compared to their non-virtual counterparts. Rarely they mention actual runtimes, just that they are slower. This knowledge will remain in your head, but at some point, when the performance becomes important, you might wonder, how slower? And why slower?
Measuring performance by counting instructions and doing all kinds of abstract reasoning rarely corresponds to the actual runtimes. In this post we will try to reason about the performance price of virtual functions. We will take into account not only instructions, but the hardware they are running and the typical ways virtual functions are used in C++ programs. So let’s start!
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
A bit of background
We will assume you know what virtual functions are. The C++ standard doesn’t mandate how to implement virtual functions in C++, but most compilers implement them in the following way. At compile time, for each type, the compiler knows which functions are virtual. It knows the address where the virtual function starts. For each type, it creates a table (called virtual table) that holds pointers to all virtual functions the type has.
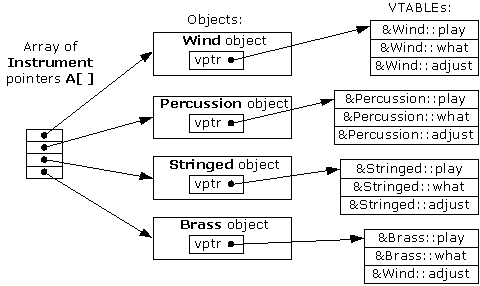
In the example in the picture, class Instrument has three virtual functions: play, what and adjust. There are four classes deriving from the class Instrument, and they implement all three virtual functions. Each type has its own virtual table.
At runtime, when the object is first created, a hidden member that points to its vtable will be created as well. Again, in the example, if the program created an object of type Brass, the vptr will be made to point to the Brass vtable. Note that each instance has a pointer to the virtual table1, but all the instances of the same type share a single virtual table (or to say it differently, there is one virtual table instance per type).

To call a virtual function, the runtime needs to get its address first. It doesn’t know its address, but it knows the offset in the virtual table that holds the address. In our example, the runtime knows that the address of the virtual function play is at offset 0, the address of the virtual function what at offset 1, etc. The runtime accesses vptr to find the address of the virtual table, adds the offset of the function it wishes to call, gets the function address, and then performs the virtual call.
The initial analysis
Knowing all this can give you a first impression about the cost. There is definitely more involved in calling a virtual function vs calling a function with a compile-time known address.
We wanted to measure the performance impact of virtual calls, so we devised a small experiment. We created a vector with 20 million objects of the same type. Then we made 20 million calls to a function using the virtual dispatch mechanism, and finally we repeated the same experiment with the same function but without virtual dispatching. Here are the numbers:
| Runtimes | Virtual function call | Non-virtual function call |
|---|---|---|
| Short and fast function | 153 ms | 126 ms |
| Long and slow function | 32.090 ms | 31.848 ms |
In the case of a short and fast function, calling using the virtual dispatch mechanism was 18% slower. For a long and slow function, the difference was much lower, less than 1%.
Is this the whole story? Actually, it is just a beginning. There are far more variables that influence the speed of virtual functions than you might think.
Vectors and memory cache misses
Virtual functions dispatching gets activated when we are accessing our objects through pointers or references. So to use it, the developers will typically create a vector (or other data structure) that contains pointers to the objects allocated on the heap.
When it comes to performance, this approach comes with a large drawback: there is no guarantee about the memory order of objects on the heap. If the neighboring pointers do not point to the neighboring objects on the heap, we can expect a large number of cache misses and large slowdowns.
This will typically not happen if all the objects in the vector are allocated at once, but if the objects are allocated on several occasions, moved, deleted, swapped, etc, each of these operations will cause the performance to suffer, little by little.
To prove this, let’s make an experiment. We create an object vector of 20 million objects and a pointer vector of 20 million pointers. We set that pointer N in the pointer vector points to the object N in the object vector. This is the perfect arrangement: all neighboring pointers point to the neighboring objects. In the next step, we pick a random element in the pointer vector and swap it with the first element. Each swap performs a light slowdown because the neighboring pointers do not point to the neighboring objects anymore. We perform more and more swaps and measure how the performance degrades.
Here is the runtime of a short virtual function depending on the number of swaps:
As you can see, the slowdown keeps growing as we are swapping more and more pointers. The slowdown takes off when about 5% of the pointers are out of place and continues to grow until all of the elements have been swapped. The best case is 7.5x faster than the worse case.
We performed the measurements for both short virtual and short non-virtual functions, and the results are very similar. So the problem aren’t virtual functions themselves, but the way you store data inside your vector.
Storing objects in a vector of object pointers, unless done very carefully, will result in slowdowns. How big the slowdown will be, we cannot tell. If you are modifying your vector a lot, it might happen the slowdown is huge, if you keep your pointers in place most of the time, the performance can be close to optimal.
Vectors of objects (as opposed to vectors of pointers) don’t have such issues. It is possible to create a vector of objects and to use virtual functions at the same time (we wrote about that in the article about polymorphic vectors), but STL doesn’t provide that kind of solution out of the box and one sees it rarely in practice. Another alternative is to give up on virtual dispatching and use per type vectors, or std::variant.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Compiler optimizations
The next difference between virtual functions and non-virtual functions is related to compiler optimizations. Remember that the address of the virtual function is known only at runtime. When we are iterating over a collection of objects, the runtime has to find out the address of virtual functions for each object independently.
In the case of non-virtual functions, the compiler does know the address of a non-virtual function. The compiler can then inline the function. This saves a few instructions for the calls to the function and returns from it, but that’s not the only optimization it does. Inlining opens a new world of compiler optimization opportunities.
With inlining the compiler can perform many compiler optimizations. It can remove the unused parameters which are passed to the function, it can move repeated operations outside of the loop. It can efficiently vectorize the loop. It can perform software pipelining: unroll a loop e.g. two times, inline the same function two times, and then interleave the operations from the two functions to better exploit underlying hardware. Etc.
To get a feeling of compiler optimizations, here is the source code we used:
class object {
protected:
bool m_is_visible;
unsigned int m_id;
static unsigned int m_offset;
public:
ATTRNOINLINE
bool is_visible() { return m_is_visible; }
ATTRNOINLINE
unsigned int get_id3() { return m_id + m_offset; };
};
// Test loop
for (int i = 0; i < arr_len; i++) {
object* o = pv.get(i);
if (o->is_visible()) {
count += o->get_id3();
}
}We compiled the code both with ATTRNOINLINE and without it. This means that in one case functions is_visible() and get_id3() will be inlined, and in other they won’t.
Please note that we are using non-virtual functions for our test. Virtual functions are by definition slower than their non-virtual counterparts; we wanted to measure the performance gains from inlining; using virtual functions would make the difference even more pronounced.
In this particular example, CLANG 10 compiler inlined the functions and unrolled the test loop two times. It also performed loop invariant code motion on the variable m_offset in the function get_id3(): it moved the variable read outside of the loop since its value doesn’t change in the loop. For the array of 20M elements, the runtime with the not-inlined function was 242 ms, and the runtime with the inlined function was 136 ms.
This is an example to show you the power of inlining. But bear in mind that in your particular case, the speed improvements can be better or it might happen there is no speed improvement or even slowdown2.
Jump destination guessing and virtual functions
Modern hardware does a lot of guesses (the technical term is speculative execution). In the case of calls to virtual functions, the hardware typically doesn’t know the jump destination until very late. To speed your program, the hardware guesses the address of the destination and starts executing instructions at the destination before the destination address is known with certainty.
If it guessed right, hurrah! If not, the CPU reverts all the work done until that point and starts executing the instructions from the correct destination. The wrong guess costs time and makes your program a bit slower. Many wrong guesses will make your program much slower.
The slowdown is especially visible in the case of short virtual functions. Luckily, modern hardware is good at prediction and if there is a pattern in the calls, the hardware will figure it out.
To demonstrate the price of jump address mispredictions, we devised an experiment. We are calling a very short virtual function on a vector of 20 M objects of different types, but the objects in the vector are sorted in three different ways:
- Sorted by type – objects in the vector are sorted by type, e.g. A, A, A, A, B, B, B, B, C, C, C, C.
- Sorted in a round-robin fashion – e.g, A, B, C, A, B, C, A, B, C, A, B, C.
- Unsorted – the arrangement of objects in the vector is random, e.g. B, C, A, C, A, C, B, B, A, C, B, A.
Here are the runtimes for all three sorting types:
If the elements in the container are sorted by type, or the types follow a certain pattern, the performance is good. But for the unsorted vector, the speed is more than 2.5x slower than for sorted vectors. This behavior is visible with short virtual functions, with long virtual functions the jump misprediction penalty will disappear in the overall functions runtime.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
Cache evictions and performance
Modern hardware is equipped with many cache subsystems that allow it to run faster. One such cache is instruction cache: instructions that are executed often are kept in this cache, so they can be fetched and decoded faster. Another cache keeps the comparison result for branch instruction: if the hardware can “guess” the destination of the branch from the previous executions of the same instruction, this speeds up the computations. Please note that these caches are limited in size, i.e. when there is no more place for the current code, the caches will evict (remove) the instructions and branch prediction results for the old code.
Stream of instruction that is executed often is in hardware terminology hot, i.e, its instructions and branch results are in the appropriate caches and it executes faster. Virtual functions, and especially large virtual functions with different implementations for each type, create a problem here.
Imagine a scenario where several different types implement a different version of the same virtual function. Your program is iterating over objects and calling the implementation of the function depending on the object type. If the container is not sorted by type, most calls to a virtual function will result in a call to a different function. If functions are large enough, the instructions in the current function will evict (remove) the data from the caches for the previous function. Virtual functions keep evicting the hardware runtime data of one another, and your hardware is always running cold code.
This behavior is the trickiest to measure because it depends on many variables:
- The number of different implementations of the virtual function – if the number is bigger, the eviction effect will be more pronounced.
- The number of executed instructions inside a virtual function – the virtual function can be large, but if only a few instructions are executed inside it, it won’t cause a huge penalty. If many different instructions are executed inside it, the effect can be very pronounced.
- How sorted is the container – contrary to jump prediction misses from the previous section, worse case happens when the types in the container are stored in a round-robin fashion – A, B, C, D, E, A, B, C, D, E, A, B, C, D, E, A, …
Let’s measure the effects of cache evictions. In our example, one vector was sorted by type, the other was sorted in a round-robin fashion. We implemented a long_virtual_function for our four test types (rectangle, circle, line and monster). We created a for loop inside the function, and in the loop body we used X macros to implement a huge if statement with many if clauses. The code looks like this:
#define VARIABLES \
V(1, a* a* a) \
V(2, a / 3) \
V(3, a / 5) \
V(4, -a / (a - 1))
int long_virtual_function(std::vector<int>& v,
int start,
int count) override {
int sum = 0;
for (int i = start; i < start + count; i++) {
int a = v[i];
if (a == 0) {
sum += a;
}
#define V(num, expr) \
else if (a == num) { \
sum += (expr) - (expr) / 2; \
}
VARIABLES
#undef V
}
return sum;
}We changed the number of if clauses inside the virtual function and wanted to observe how this affects the runtime. Here are the numbers:
When the virtual function is small, it doesn’t matter if the objects in the vector are sorted or not. As the size of the virtual function grows, the effects of cache eviction become more and more apparent. In the worst case, the same function took 7.5 seconds to execute in the sorted vector, and 12.3 seconds to execute in the round-robin vector.
Again, this phenomenon is not tied to virtual functions themselves. The same effect can be achieved with function pointers. However, in the environment where virtual functions are used this problem is much more likely to occur.
Final Words
What is the moral of this story? My personal opinion is that the virtual functions themselves are not the major source of slowness in C++ programs, but they however enable some bad practices that eventually lead to low hardware utilization and bad performance.
What the hardware craves is predictability: same type, same function, neighboring memory addresses. If it has that, it will run its fastest. If not, some kind of performance penalty will need to be paid. What the price is, depends.
If you do plan to use virtual functions, pay attention to the following:
- Arrangement of objects in memory is very important! If your objects are scattered in the memory, the performance will be very poor. A workaround is a custom memory allocator for your vector of pointers or a polymorphic_array as we described in our previous post.
- Try to make small functions non-virtual! Most overhead of virtual functions comes from small functions, they cost more to call than to execute. Also, the compiler is really good at optimizing small virtual functions.
- Keep objects in the vector sorted by type. This will allow the most efficient utilization of instruction caches and branch prediction caches, making your code fast.
Do you need to discuss a performance problem in your project? Or maybe you want a vectorization training for yourself or your team? Contact us
You can also subscribe to our mailing list (link top right of this page) or follow us on LinkedIn , Twitter or Mastodon and get notified as soon as new content becomes available.
A note
Modern C++ has a very powerful template mechanism that you can use to replace the virtual dispatching mechanism. A proof of concept is multivector, a vector that can hold several different types. Internally, each type has its own vector, and when the objects are initially pushed to the multivector, they will be kept in the vector for their corresponding type.
Class multivector can use lambda expressions to call functions for different types with a simple syntax. Example:
// Multivector that can hold circles, lines, rectangles and mosters
jsl::multivector<circle, line, rectangle, monster> mv;
bitmap b(640, 480);
// Filling the container with random shapes
fill_container(mv, arr_len, SORTED, 640, 480);
// Drawing shapes
mv.for_all([&b](auto& o) { o.draw(b); });The above code declares a multivector that can hold types circle, line, rectangle and monster. The line mv.for_all([&b](auto& o) { o.draw(b); }); will call method draw for all the objects in the vector, regardless of their type. The call is not made using virtual dispatching, but for each object type there is a separate loop iterating through the type’s vector and calling the lambda function passed as the argument.
This code is clean, and it can be very fast. However, using multivector in many places can result in code bloat and poor code locality. So use with care. If you use multivector in your project, make sure to drop us a note on your experiences.
- If the class doesn’t have any virtual functions, then
vptrwill naturally be absent [↩] - I saw slowdowns in a few cases examples on really large functions because: (a) the compiler got confused because of the function size and skipped some important optimization opportunities and (b) after the inlining the critical code became too large and did not fit the instruction caches. These cases are rare in practice. [↩]
> Try to make small functions non-virtual! Most overhead of virtual functions comes from small functions, they cost more to call than to execute. Also, the compiler is really good at optimizing small virtual functions.
This is confusing. If the compiler is good at optimization, why would you worry about avoiding them? Perhaps this is a typo?
The compiler is good at optimizing non-virtual functions much better than optimizing virtual functions (because of inlining). So, if there is a way to get rid of calls to virtual functions by replacing them with non-virtual functions, this enables the compiler to do more optimizations. E.g. you have class `Base` and three derived classes `A`, `B`, `C` and they have a virtual method `get_id()` which returns 1 for `A`, 2 for `B` and 3 for `C`. To move to non-virtual solution, you can create a member variable inside `Base` called `my_id`. When the constructor of `A`, `B` or `C` gets called, it initialized `my_id` with a corresponding value. Since the method `get_id()` doesn’t need to be virtual, it can be inlined and if you’re lucky the compiler can optimize better. But, with compiler optimizations, there is always an element of “luck”, sometimes, this change might not bring speed improvements. Always measure!
This is where if C++ had a JIT compiler / runtime analysis (like say JVM / CLR), many situations where we want virtual managed to get situationally optimised into direct calls and even inlined. IMO, the C++ compiler and runtime concept is too primitive / restricted.
If the vector of pointers points to different types, then JIT compilation won’t help. And, my take is that if you are already using polymorphism, then this is probably the case.
But yes, the type of optimizations possible with JIT would make certain workloads much faster, including the one your described.
Funny usage of the word “primitive” given that JVM and CRL are like turtles in comparison to the good old compiled code.
This may sound as nitpicking, but this doesn’t sound right: “At runtime, when the object is first created, the compiler will create a hidden member”. I’m pretty sure that the compiler won’t do anything at runtime.
You are right, it is a bad phrase. The compiler doesn’t do anything once it emits binary. I am fixing it.
Saying a non-virtual function executes faster than a virtual function is misleading. It ignores the decision process in determining which non-virtual function to execute.
It should be underscored that this article refers to high-end processors. With smaller systems used for embedded systems, there is no caching. Depending on the processor virtual dispatch can be significantly faster.
Other thing that bothers me, is that article doesn’t mention that any branching mechanism deep inside the most nested loop can cause performance penalties on high end processors.
And the most important is that there are cases where dynamic branching is the only viable solution.
I don’t understand, what kind of branching are you referring too.
By static branching I mean choosing to what code to execute next with if or switch statements, and by dynamic using something like function pointers to do that. Please forgive me, If it is not common terminology, English is not my first language.
My criticism of your article last points, is that switch statements inside the deepest loop can have similar effect on performance.
Also virtual functions or function pointers can be the only viable solution in case when you going to ship some code possibly dealing with any user defined types.
I can add a data point: compiler authors are investing in devirtualization and do measure some tangible speedups. Here’s one recent (2020) work on de-virtualization in clang (https://arxiv.org/pdf/2003.04228.pdf) where the abstract says “Our benchmarks show an average of 0.8% performance improvement on real-world C++ programs, with more than 30% speedup in some cases. ” So here’s one estimate for (at least part of) the overall cost of virtual calls.